-
DOWNLOAD THE RDF DATA
-
Go to http://dbserver.acoli.cs.uni-frankfurt.de:5006/ and download/unzip the dictionaries of your choice in a local folder.
-
INSTALL AND RUN THE TRIPLE STORE
-
Download Apache Jena Fuseki from https://jena.apache.org/download/ (documentation cab be found at https://jena.apache.org/documentation/fuseki2/)
-
Unzip it into a local folder of your choice
-
Go to the installation folder and run, in console mode: ./fuseki-server The server is accesible at http://localhost:3030/
-
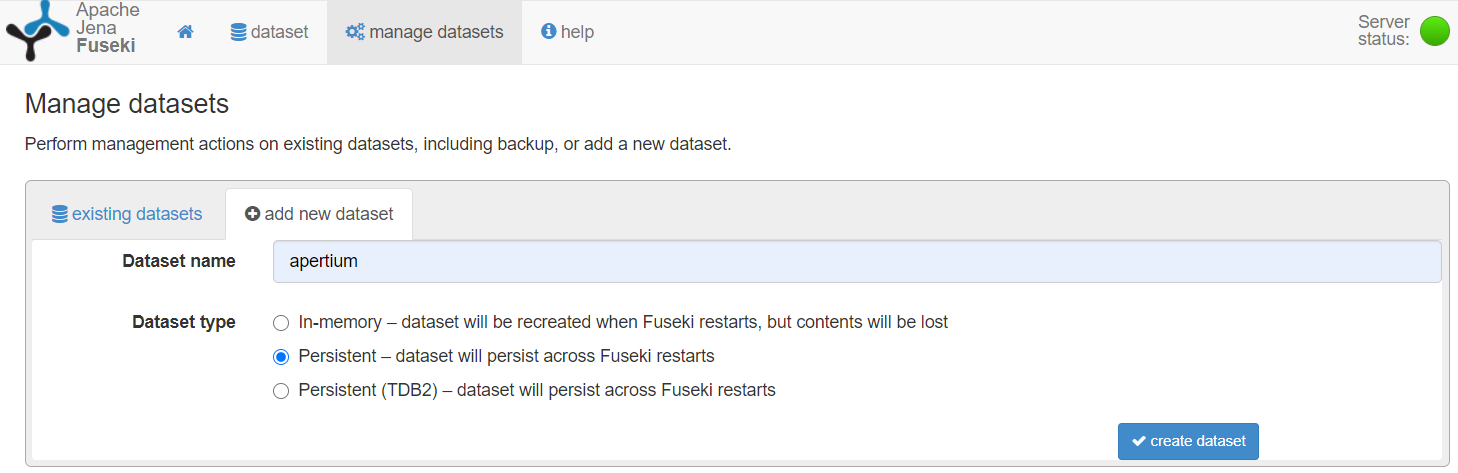
ADD A NEW DATASET
-
Go to "manage datasets" and create
a new "persistent" one. You can name it "apertium", for instance
-
Then, click on "upload data" and select the dictionary files you want to store in the dataset. For instance, go to the "apertium-an-ca-rdf" folder and select the three files on it (two lexicons monolingual lexicons + one translation set)
-
RUN A SPARQL QUERY
-
Now you can run SPARQL queries in the "query" tab. For instance this one to get the number of translations per translation set:
PREFIX ontolex: <http://www.w3.org/ns/lemon/ontolex#>
PREFIX skos: <http://www.w3.org/2004/02/skos#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX vartrans: <http://www.w3.org/ns/lemon/vartrans#>
PREFIX lime: <http://www.w3.org/ns/lemon/lime#>
SELECT ?trSet count(?trans)
WHERE {
?trSet a
vartrans:TranslationSet ;
vartrans:trans
?trans .
}
group by ?trSet